Simple Web Page Scraping Using Beautiful Soup and Python
Mike Kock · Mar 28, 2023
Web Page Scraping
Perhaps you have a website with a lot of content but users might have a hard time finding the information they are looking for on the site. Or there is so much content and detail that users just don't want to spend the time reading that much text. Building a search engine for your site might be one solution.
In order to do this you will need to first scrape all the text content from your website. You could visit all the pages manually and save them to disk but this would be tedious and time consuming, especially for a large site that constantly changes. This is a perfect job for a computer. So, you are going to need to write some code to discover and fetch the content from the various web pages. There are many different libraries our there to help you do this. The Beautiful Soup Python library is a popular and simple to use library that we can use to help scrape the content from a web page.
Sample code for this project can be found on my Github Page
Beautiful Soup Setup
To get started, we need to install the Beautiful Soup library. We can do this by adding beautifulsoup4 to your requirements.txt file. You probably also want to add requests to your requirements.txt file as well so you can programmatically fetch pages from your website. Then you can install the libraries by opening a terminal and running the following command:
pip install -r requirements.txt
Then in your Python code you can import the library:
from bs4 import BeautifulSoup
import requests
Fetching a Web Page
Before you can get the content from a web page you need to fetch the page. The requests library makes this easy. You can fetch a page by calling the get method on the requests library and passing in the URL of the page you want to fetch.
base_url = 'https://blog.smokinserver.com'
index_url = base_url
response = requests.get(index_url)
html = response.text
Crawling a Website
In this case we have fetched our site's main index page that contains links to all the other pages on the site. We want to crawl the site and fetch all the pages. We can do this by parsing the HTML of the page and looking for the article links. First we need to determine how to identify the article links. We can do this by looking at the HTML source of the page and with the help of the inspect element feature in the browser. Right click one of the article links and select Inspect Element. This will open the developer tools and highlight the HTML element that was clicked.
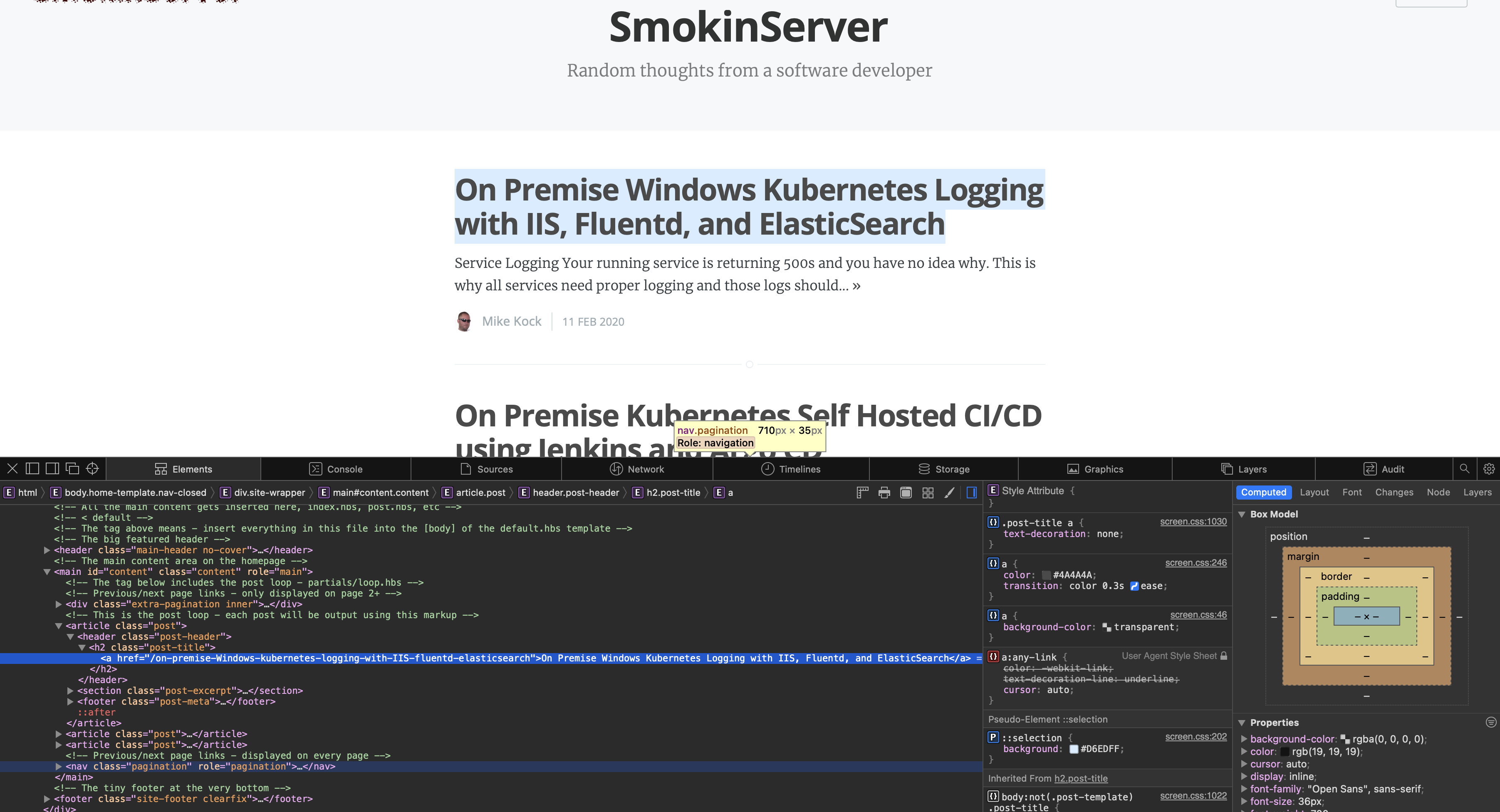
Here we can see the <a href=> tag that contains the link to the article is under a h2 tag with class "post-title". We will use this information to find all the post links on the page.
Parsing the HTML
Now we can use the Beautiful Soup library to help us parse the HTML and find the article links and save them to a list.
soup = BeautifulSoup(html, 'html.parser')
posts = []
post_rows = soup.find('h2', attrs={'class': 'post-title'}).find_all('a', href=True)
for post in post_rows:
url = post.get('href')
title = post.get_text()
posts.append({'url': base_url + url, 'title': title})
The soup.find() allows us to find all kinds of different HTML elements based on the type of element and specific attribute values. In this case we are looking for all of the h2 elements with class "post-title" and then under those elements we are looking for all the a elements with a href attribute. We then get the relative site URL from the href attribute and the title from the page text of the a element.
Fetching the Article Content
Now that we have a list of all the article links we can fetch the content of each article. We can do this by iterating over the list of posts and fetching each page. Our approach will be very similar to what we did for the index page. We will uses requests to download the HTML page, figure out which elements contain the article content ( tag with a class of "post") and then use Beautiful Soup library to find those elements and get the plain text.
for post in posts:
print(f"Scraping {post['title']}")
response = requests.get(post['url'])
html = response.text
soup = BeautifulSoup(html, 'html.parser')
content = soup.find('article', attrs={'class': 'post'}).get_text()
Conclusion
There we go. With a handful of lines of Python code we are able to dynamically fetch a webpage containing links to other pages and then crawl those other pages to get the raw text content. At this point we can do whatever we want with the content. If we wanted we could calculate text embeddings for each page and build a semantic search index which we can then use for a chatbot that can leverage relevant page content from the site in order to answer user questions in natual language. Perhaps we will save that for another blog post.